Over the last couple of weeks I’ve been trying to build a working CalculiX 2.21 solver with PaStiX on FreeBSD 14 (x86-64) without CUDA. I’m using GCC 13 (and gfortran13) for the build.
Libraries built (in order):
- spooles 2.2 + FreeBSD patches + my patches to fix warnings
- OpenBlas 0.3.26
- arpack ng 3.9.1
- hwloc 2.10.0
- mfaverge-parsec-b580d208094e
- scotch 6.0.8
- PaStiX4CalculiX (cudaless branch from https://github.com/Kabbone/PaStiX4CalculiX)
Spooles is built like this:
make global -f makefile
cd MT/src
make -f makeGlobalLib
OpenBlas is built with:
env CC=gcc13 FC=gfortran13 AR=gcc-ar13 \
NO_SHARED=1 INTERFACE64=1 BINARY=64 USE_THREAD=0 \
gmake
(This was the problem; see the end of this post.)
Arpack:
autoreconf -vif
env INTERFACE64=1 CC=gcc13 F77=gfortran13 FC=gfortran13 \
LDFLAGS=-L${PREFIX} \
./configure --with-blas=-lopenblas --with-lapack=-lopenblas --enable-icb --enable-static --disable-shared --prefix=${PREFIX}
gmake
hwloc:
env CC=gcc13 CXX=g++13 LIBS='-lexecinfo -lpciaccess'\
./configure \
--prefix= ${PREFIX}\
--disable-shared --enable-static \
--disable-readme --disable-picky --disable-cairo \
--disable-libxml2 --disable-levelzero
parsec:
cmake \
-Wno-dev \
-DEXTRA_LIBS='-lexecinfo -lpciaccess' \
-DNO_CMAKE_SYSTEM_PATH=YES \
-DCMAKE_INSTALL_LOCAL_ONLY=YES \
-DBUILD_SHARED_LIBS=OFF \
-DCMAKE_CXX_COMPILER=g++13 \
-DCMAKE_C_COMPILER=gcc13 \
-DCMAKE_Fortran_COMPILER=gfortran13 \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_INSTALL_PREFIX=${PREFIX} \
-DPARSEC_GPU_WITH_CUDA=OFF \
-DHWLOC_DIR=${PREFIX} \
..
gmake -j4
scotch was built using the following Makefile.inc:
EXE =
LIB = .a
OBJ = .o
MAKE = gmake
AR = ar
ARFLAGS = -ruv
CAT = cat
CCS = gcc13
CCP = mpicc
CCD = gcc13
CFLAGS += -std=c99 -fPIC -DCOMMON_FILE_COMPRESS_GZ -DCOMMON_PTHREAD
CFLAGS += -DCOMMON_RANDOM_FIXED_SEED -DSCOTCH_RENAME -DSCOTCH_RENAME_PARSER
CFLAGS += -DSCOTCH_PTHREAD -Drestrict=__restrict -DIDXSIZE64
CFLAGS += -DINTSIZE64 -DSCOTCH_PTHREAD_NUMBER=4 -DCOMMON_PTHREAD_FILE
CLIBFLAGS =
LDFLAGS += -lz -lm -lpthread
CP = cp
LEX = flex -Pscotchyy -olex.yy.c
LN = ln
MKDIR = mkdir -p
MV = mv
RANLIB = ranlib
YACC = bison -pscotchyy -y -b y
If you have a CPU with more or less than four cores, you might want to adapt -DSCOTCH_PTHREAD_NUMBER=4 accordingly.
The original PaStiX4CalculiX does not build without CUDA. Even if configured without CUDA it references CUDA functions and types and fails.
Luckily I found Kabbone’s version before I was halfway fixing all the errors.
With Kabbone’s PaStiX4CalculiX I can build PaStiX if and only if Python 2 is used to generate the different versions of the code. The Python scripts in PaStiX4CalculiX fail miserably with Python 3.
Building PaStiX is done as follows.
(The patch for CMakeLists.txt is used to tell cmake to use gcc-ar13).
patch < ../../patches/pastix/kabbone-CMakeLists.txt.patch
mkdir build
cd build
env PKG_CONFIG_PATH=/zstorage/home/rsmith/tmp/src/calculix-build/lib/pkgconfig \
cmake -Wno-dev \
-DPYTHON_EXECUTABLE=/usr/local/bin/python2.7 \
-DPASTIX_WITH_CUDA=OFF \
-DCMAKE_PREFIX_PATH=${PREFIX} \
-DCMAKE_INSTALL_PREFIX=${PREFIX} \
-DCMAKE_BUILD_TYPE=Release \
-DPASTIX_WITH_PARSEC=ON \
-DSCOTCH_DIR=${PREFIX} \
-DPASTIX_ORDERING_SCOTCH=ON \
-DCMAKE_C_COMPILER=gcc13 \
-DCMAKE_CXX_COMPILER=g++13 \
-DCMAKE_Fortran_COMPILER=gfortran13 \
-DCMAKE_C_FLAGS='-fopenmp -lpciaccess -lm -Wno-unused-parameter' \
..
gmake -j4
gmake install
(On FreeBSD, GNU make is called gmake)
The following Makefile was used to build ccx:
PASTIX_INCLUDE = ../../include/
DIR=../spooles
WFLAGS = -Wno-unused-variable -Wno-unused-argument -Wno-maybe-uninitialized
WFLAGS += -Wno-unused-label -Wno-conversion
CFLAGS = -Wall -O2 -fopenmp -fpic -I$(DIR) -I$(PASTIX_INCLUDE) -DARCH="Linux" -DSPOOLES -DARPACK -DMATRIXSTORAGE -DINTSIZE64 -DPASTIX -DPASTIX_FP32 $(WFLAGS)
FFLAGS = -Wall -O2 -fopenmp -fpic -fdefault-integer-8 $(WFLAGS) -Wno-unused-dummy-argument
CC=gcc13
FC=gfortran13
.c.o :
$(CC) $(CFLAGS) -c $<
.f.o :
$(FC) $(FFLAGS) -c $<
include Makefile.inc
SCCXMAIN = ccx_2.21.c
OCCXF = $(SCCXF:.f=.o)
OCCXC = $(SCCXC:.c=.o)
OCCXMAIN = $(SCCXMAIN:.c=.o)
PASTIX_LIBS = -lpastix -lpastix_kernels -lpastix_parsec -lparsec -lhwloc -lspm
PASTIX_LIBS += -lscotch -lscotcherrexit -lopenblas
PASTIX_LIBS += -lgomp -lstdc++ -lpciaccess -latomic -lexecinfo
LIBS = -L../../lib \
$(DIR)/spooles.a \
-larpack \
$(PASTIX_LIBS) \
-lpthread -lm -lz -lc
ccx_2.21_i8: $(OCCXMAIN) ccx_2.21.a
./date.pl; $(CC) $(CFLAGS) -c ccx_2.21.c; $(FC) -Wall -O2 -o $@ \
$(OCCXMAIN) ccx_2.21.a $(LIBS)
ccx_2.21.a: $(OCCXF) $(OCCXC)
ar vr $@ $?
With that I could build and link ccx.
An example problem seems to run OK; it finishes without errors.
However the results generated by that executable are invalid.
Note that using the same libraries but building without PaStiX (just using spooles, arpack and openblas) works fine:

When I use the executable built with PaStiX:
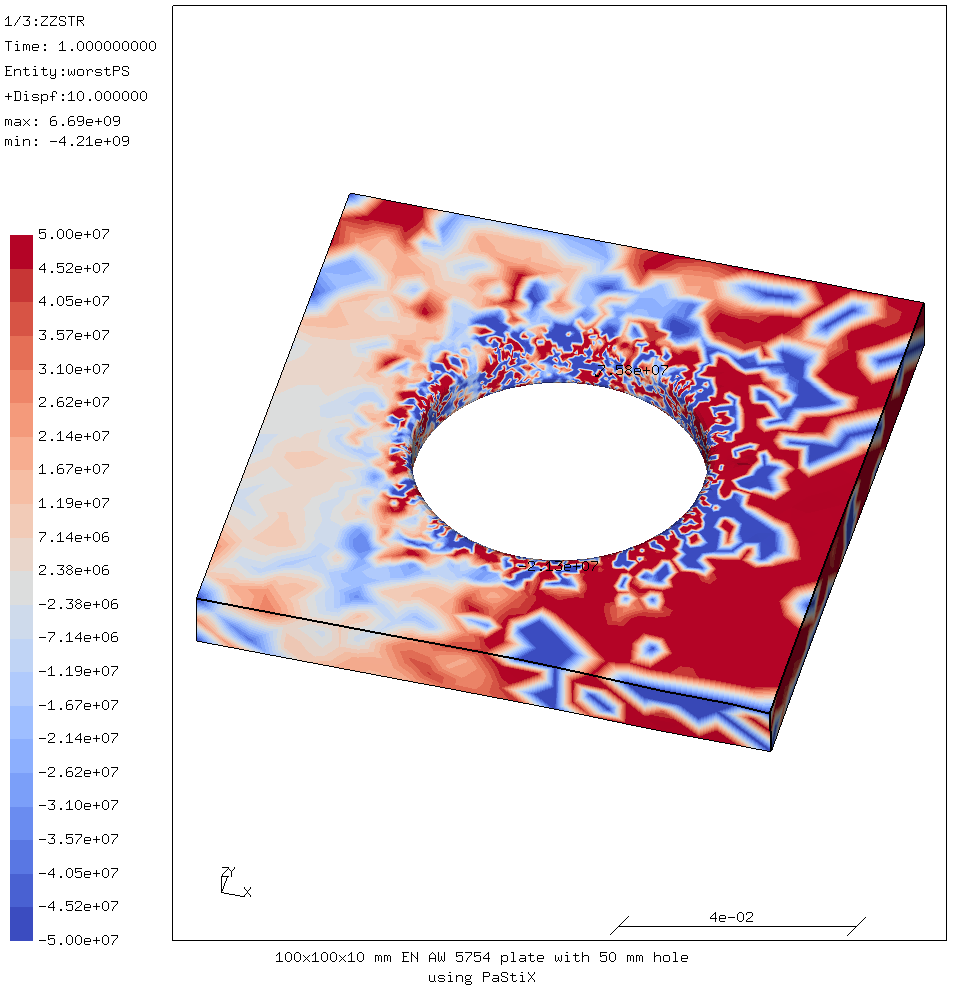
So I strongly suspect PaStiX is the problem. (Actually it was OpenBLAS not using locking.)
What I’m not sure of is what exactly the problem is. On the one hand, it looks like some kind of memory corruption issue. On the other hand, I’m not sure if the scripts that generate different versions of the code work as they should.
I also found a set of patches that supposedly enabled a stock PaStiX 6.2.0 to work with CalculiX. And although that compiled and ran, it failed with NaN results on the example problem.
If anyone could give me a pointer as to what is going wrong and how to fix it, I’d appreciate it.
PROBLEM SOLVED
So, after a lot of experimentation, I found the solution.
Basically, even though OpenBLAS is built as a single threaded library, it needs to be built with locking enabled because CalculiX uses it with multiple threads. As usual with these things, pretty obvious in hindsight.
![]()
So, the correct invocation to compile OpenBLAS is:
# Do *not* use USE_OPENMP=1. Pastix needs a singe-threaded build, hence USE_THREAD=0.
# Enable locking in case BLAS routines are called in a multithreaded program.
env CC=gcc13 FC=gfortran13 AR=gcc-ar13 \
PREFIX=${PREFIX} \
NO_SHARED=1 INTERFACE64=1 BINARY=64 USE_THREAD=0 \
BUFFERSIZE=25 USE_LOCKING=1 DYNAMIC_ARCH=1 \
gmake
I used DYNAMIC_ARCH=1 so I can hopefully also use the same binary on a machine with another CPU type. If you don’t need that you can leave it out and speed up the build significantly.
Thanks to all for the assistance.
The scripts and patches I’ve used are available on github in case anybody wants to use them.
